


Crawler là gì? Hướng dẫn xây dựng Web Crawler đơn giản
Nội Dung ChínhCrawl là gì?Web Crawler là gì?Những tên gọi của Web Crawler là gì?Yếu tố nào ảnh hưởng đến Website Crawler?Bots crawl website có nên được truy cập các thuộc tính web không?Việc quản lý bot quan trọng như thế nào đến việc thu thập dữ liệu web?So sánh giữa Web Crawling và Web … Tiếp tục đọc Crawler là gì? Hướng dẫn xây dựng Web Crawler đơn giản
Web crawler là khái niệm không còn mấy xa lạ đối với người dùng web và các marketers. Chúng có nhiệm vụ chính là duyệt website một cách có hệ thống trên mạng World Wide Web. Từ đó, chúng có thể thu thập thông tin của những website này về cho công cụ tìm kiếm. Vậy bạn đã biết Crawl là gì và cách xây dựng Web Crawler như thế nào chưa? Để tìm câu trả lời chi tiết nhất, hãy cùng Vietnix tìm hiểu ngay trong bài viết dưới đây nhé!
Crawl là gì?
Crawl hay còn được gọi với cái tên khác là cào dữ liệu (Crawl Data hay Crawl dữ liệu). Đây là một thuật ngữ được đánh giá là không còn quá xa lạ trong Marketing, đặc biệt là đối với SEO. Bởi lẽ, crawl chính là kỹ thuật mà robots của các công cụ tìm kiếm như Google, Bing hay Yahoo,… sử dụng.
Công việc chính mà crawl đảm nhiệm là thu thập dữ liệu từ một trang web bất kỳ. Sau đó, chúng sẽ tiến hành phân tích mã nguồn HTML nhằm mục đích đọc dữ liệu. Cuối cùng, dữ liệu sẽ được lọc ra theo yêu cầu của người dùng hoặc Search Engine.

Web Crawler là gì?
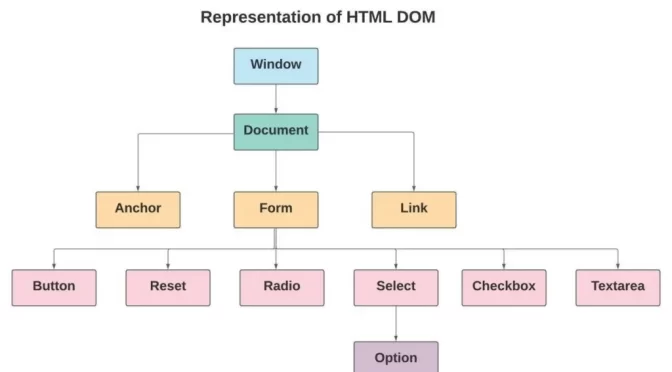
Web crawler (Trình thu thập thông tin web), Spider hay bot công cụ tìm kiếm có chức năng tải xuống đồng thời Index toàn bộ Content từ khắp mọi nơi trên Internet. Từ “crawl” trong cụm “Web crawler” tượng trưng cho một kỹ thuật dùng để chỉ quá trình truy cập website một cách tự động và lấy data thông qua một chương trình phần mềm.
Mục tiêu của bot là tìm hiểu xem các trang trên website nói về điều gì. Từ đó, chúng sẽ tiến hành xem xét truy xuất thông tin khi cần thiết. Các bot này hầu hết đều được vận hành bởi các công cụ tìm kiếm.

Bằng phương pháp áp dụng thuật toán tìm kiếm cho dữ liệu thu thập được bởi web crawl (data crawling), công cụ tìm kiếm sẽ có thể cung cấp các liên kết có liên quan mật thiết nhằm đáp ứng các truy vấn tìm kiếm của người dùng. Sau đó, nó sẽ tạo ra danh sách các trang web cần hiển thị khi người dùng nhập từ khóa vào ô tìm kiếm của Google, Yahoo hoặc Bing,…
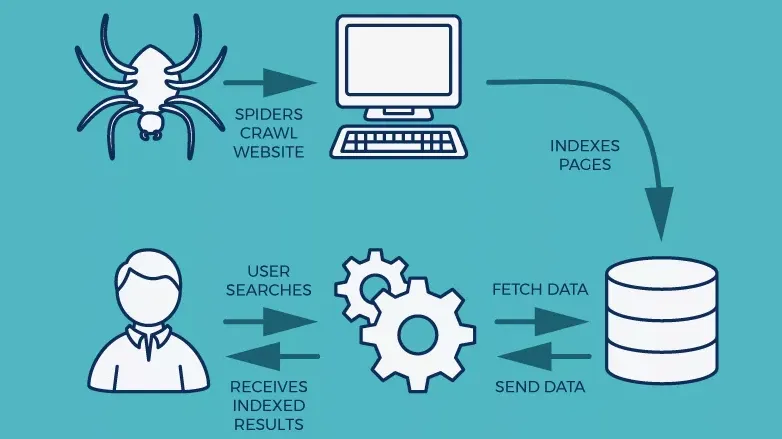
Những tên gọi của Web Crawler là gì?
Crawl data có nhiều tên gọi: Spider, Ant, Bot công cụ tìm kiếm,… Cụ thể như sau:
- Spider: Đây được coi là cách gọi hình tượng hóa của crawl. Bởi lẽ, nguyên lý hoạt động cũng như lưu trữ thông tin của website crawler có tính tương đồng cao so với hoạt động của một con nhện. Theo đó, bắt đầu từ một website bất kỳ, Spider sẽ có xu hướng len lỏi vào từng ngóc ngách trong trang web đó đồng thời truy cập một cách lần lượt vào từng liên kết có trên trang.
- Ant: Tương tự như Spider, Ant cũng dựa trên cách thức lưu thông tin của trang web và các hoạt động của web crawler. Theo đó, khi di chuyển, một con kiến sẽ thường tiết ra một loại chất có tên pheromone để lưu lại dấu vết mà nó đã đi qua. Việc đánh dấu liên kết như vậy của Ant trên website cũng giống với việc tạo ra tơ nhện của Spider.
- Crawler: Đây là cách gọi dựa theo chính chức năng của website crawler. Với tên gọi này, nó có thể mô tả các hành động truy cập cũng như thu thập dữ liệu của crawl trên một website giống với một người hoặc con bọ đang bò trườn trên trang đó.
- Bot (Internet Bot): Đây là một phần mềm ứng dụng chạy trên Internet một cách tự động. Có thể nói rằng, web crawler chính là tập hợp con của Internet Bot.
Yếu tố nào ảnh hưởng đến Website Crawler?
Hiện nay, có rất nhiều yếu tố ảnh hưởng đến tỷ lệ crawl và index. Dưới đây, là một số yếu tố chính góp vai trò quan trọng trong việc crawl và index của Google:
- Domain: Khi tên miền có chứa từ khóa chính được đánh giá tốt thì website crawler tốt cũng sẽ có được thứ hạng cao trên kết quả tìm kiếm. Trong khi Google Panda được ra đời để đánh giá chất lượng của một domain, thì việc sở hữu một domain chất lượng được quan tâm hơn bao giờ hết.
- Backlink: Các backlink chất lượng đóng vai trò quan trọng góp phần giúp website thân thiện với công cụ tìm kiếm hơn. Nếu nội dung trên trang của bạn tốt nhưng lại không xuất hiện backlinks nào, thì Google sẽ chỉ định website của bạn kém chất lượng, không cung cấp nội dung giá trị cho độc giả.
- Internal Link: Internal Link là các liên kết nội bộ trong một website, là một trong những yếu tố bắt buộc nhất định cần phải có khi làm SEO. Không những thế, nó còn giúp giảm tỷ lệ rời trang web đồng thời tăng thời gian onsite của người dùng.
- XML Sitemap: Sitemap giúp Google có thể nhanh chóng index hoặc cập nhật bài viết một cách nhanh nhất có thể.
- Duplicate Content: Việc website trùng lặp nội dung sẽ bị Google block. Chính vì vậy, bạn hãy khắc phục lỗi chuyển hướng 301 và 404 để được crawling cũng như SEO tốt hơn.
- URL Canonical: Việc tạo đường dẫn URL thân thiện với SEO cho tất cả các trang trên website sẽ góp phần hỗ trợ tối đa cho website.
- Meta Tags: Việc chèn thêm những meta tags độc đáo sẽ giúp bạn có thể đảm bảo được website có thứ hạng cao trên kết quả tìm kiếm.

>> Nếu bạn chưa biết cách xây dựng Backlink chất lượng hãy tham khảo ngay bài viết này: Backlink là gì? Cách tìm và xây dựng backlink chất lượng cho website dành cho người mới.
Bots crawl website có nên được truy cập các thuộc tính web không?
Việc các bots crawl website liệu có nên truy cập các thuộc tính web hay không còn phụ thuộc khá nhiều vào thuộc tính của web đó cùng một số yếu tố kèm theo khác. Theo đó, sở dĩ mục đích của việc web crawler yêu cầu nguồn từ máy chủ là nhằm lấy cơ sở index nội dung. Chính vì thế, tùy thuộc vào số lượng trang trên website hoặc số lượng nội dung trên mỗi trang mà các nhà vận hàng trang web sẽ cân nhắc xem liệu có nên index các tìm kiếm một cách thường xuyên hay không. Bởi lẽ, khi index quá nhiều sẽ có thể khiến cho máy chủ bị hỏng hoặc tăng chi phí băng thông.

Việc quản lý bot quan trọng như thế nào đến việc thu thập dữ liệu web?
Bot hiện nay được phân chia thành 2 loại chính đó là bot độc hại và bot an toàn. Theo đó, bot độc hại có thể sẽ gây ra cực kỳ nhiều thiệt hại nghiêm trọng, chẳng hạn như giảm trải nghiệm người dùng, gây sự cố máy chủ, hay thậm chí là đánh cắp dữ liệu. Để chặn loại bot độc hại này, bạn hãy cho phép bot an toàn truy cập vào các thuộc tính web, điển hình là crawl.
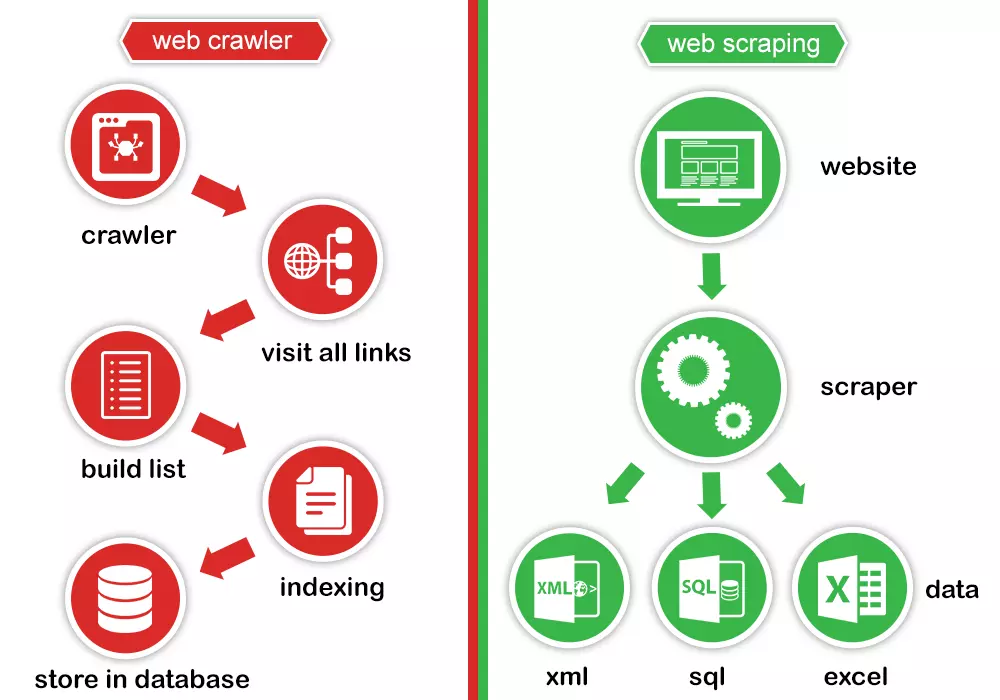
So sánh giữa Web Crawling và Web Scraping
Web scraping hay còn được gọi là data scraping hoặc content scraping. Đây là tượng trưng cho hành động một con bot tải xuống nội dung trên một trang web nào đó mà không nhận được sự cho phép của chủ website, thường là mục đích xấu.
Web scraping thường được nhiều target hơn so với web crawling. Theo đó, web scrapers chỉ có thể theo dõi một số trang web cụ thể. Trong khi đó, Web Crawling sẽ theo dõi các liên kết đồng thời thu thập thông tin từ các trang một cách liên tục. Ngoài ra, web scraper bots còn có thể qua mặt máy chủ một cách cực kỳ dễ dàng, khác hẳn so với web crawlers.
Tại sao Web Crawlers được gọi là ‘spiders’?
Trên thực tế, World Wide Web chính là nơi xuất phát “www” của phần lớn các URL của trang web. Việc gọi tên web crawlers là “spiders” là điều hoàn toàn tự nhiên. Bởi lẽ, chúng sẽ có xu hướng thu thập dữ liệu trên mọi trang web, tương tự như các con nhện bò trên mạng nhện của chúng.
Các spider ảnh hưởng thế nào đến SEO?
SEO sẽ đóng vai trò quan trọng giúp trang có thể index và hiển thị trong danh sách kết quả tìm kiếm. Trong trường hợp spider bot không thu thập dữ liệu thì chắc chắn trang web đó sẽ không thể hiển thị được trên kết quả tìm kiếm.
Những loại Web Crawler nào đang hoạt động trên Internet?
Các bot công cụ tìm kiếm nổi bật hiện nay thường được gọi như sau:
- Google: Googlebot.
- Bing: Bingbot.
- Yandex: Yandex Bot.
- Baidu: Baidu Spider.

Cách xây dựng một web crawler đơn giản
Một ví dụ minh họa về việc lấy thông tin từ trang https://vietnix.vn/ như sau:
Cài đặt:
gem "mechanize"
bundle install
Crawl data: Khởi tạo đối tượng.
agent = Mechanize.newTại đây, bạn sẽ có một danh sách như sau:
page = agent.get "https://vietnix.vn/thue-may-chu/" + "/#page_number".Để lấy được thông tin từ từng page, bạn cần có được cấu trúc của trang.
Như vậy, bạn đã có id của từng trường nên có thể lấy như sau:
crawled_page = Mechanize.new.get room_url
#get price
crawled_page.at("#ContentPlaceHolder2_lbGiaTien").try :text
#get area
crawled_page.at("#ContentPlaceHolder2_lbDienTich").try :textĐể lấy thông tin chi tiết, bạn hãy truy cập vào từng trang đã lấy ở trên:
room_url = "https://vietnix.vn/" + link.attributes["href"].try :value
page.search("#ContentPlaceHolder2_KetQuaTimKiem1_Pn1 [class^=a-title]").each do |link|
crawl_room room_url
end
private
def crawl_room room_url
crawled_params = Crawlers::RoomFromVietnix.new(room_url).crawled_params
room = Room.find_or_initialize_by code: crawled_params[:code], provider_site_cd: crawled_params[:provider_site_cd]
room.assign_attributes crawled_params
room.save
endNhư vậy, chỉ với những bước đơn giản Vietnix vừa giới thiệu ở trên bạn đã có thể hoàn thành quá trình crawl nhanh chóng và dễ dàng.
Lời kết
Thông qua bài viết trên của Vietnix, chắc hẳn các bạn đã hiểu rõ cách xây dựng cũng như tầm quan trọng của web crawler đến thứ tự xếp hạng của website trên các công cụ tìm kiếm rồi phải không nào? Hãy bắt tay chỉnh sửa website của mình ngay hôm nay để chúng luôn hoạt động theo cách hiệu quả nhất với các bot công cụ tìm kiếm nhé!


































 Nhận báo giá
Nhận báo giá